Flink Sharing Session I
06 May 2020 | flink | ArchitectureWhat’s Apache Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale. => To see Flink as a streaming framework.
A Brief Introduction to Streaming
Some vivid paragraphs are referrenced from this great article.
Processing data in a streaming fashion becomes more and more popular over the more “traditional” way of batch-processing big data sets available as a whole. The focus shifted in the industry: it’s no longer that important how big is your data, it’s much more important how fast you can analyse it and gain insights. That’s why some people are now talking about fast data instead of the now old-school big data. Borrowing the definition of streaming from Tyler Akidau:
[streaming is] a type of data processing engine that is designed with infinite data sets in mind
We can never really hope to get a “global” view of a data stream. Hence, to get any value from the data, we must somehow slice the data into partitions. Usually, we take a “current” fragment of the stream and analyse it.
To illustrate ‘current’, it may be the latest 5 minutes, the last 24 hours or the recent 5 events which all depends on your use cases.
Great articles are instroducing streaming concepts in depth are presented: Streaming 101 and Streming 102, but we are not going to dive into the articles in detail here. Just to introduce some useful concepts which will help us have a clear picture of streaming:
What’s Time
- event-time - a logical, data-dependent timestamp, embedded in the event (data element) itself. Most useful and most troubling: may be late or arrive out of order.
- ingestion-time - a timestamp assigned to the event when it enters the system
- processing-time - the wall-clock time when the event is processed. The easiest, because it is monotonic, but also less useful.
Types of Windows
- fixed/tumbling - time is partitioned into same-length, non-overlapping chunks. Each event belongs to exactly one window
- sliding - windows have fixed length, but are separated by a time interval (step) which can be smaller than the window length. Typically the window interval is a multiplicity of the step. Each event belongs to a number of windows ([window interval]/[window step]).
- session - windows have various sizes and are defined basing on data, which should carry some session identifiers
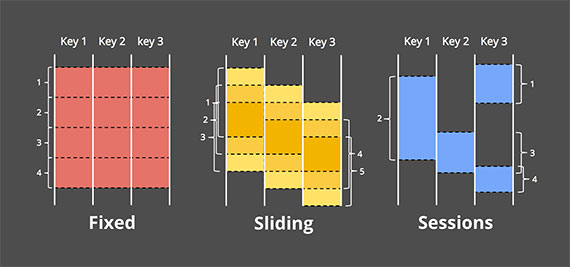 Figure 1 Example Window Strategies by Tyler Akidau
Figure 1 Example Window Strategies by Tyler Akidau
Question: what’s the window used to define derived variables in RCDL?
Out-of-order handling
As we hinted when discussing event-time, events can arrive out of order, but we can’t keep all windows around forever, as this would eat all available memory. At some point, a window has to be considered “done” and garbage collected. (There indeed a concept called global window, but seldomly used)
This is handled by a mechanism called watermarks: specifies that we assume that all events before X have been observed. Assume here indicates that watermarks are heuristic, which is a balance between including as much late data as possible and not delaying final window processing too much.
Triggers
After it defined a way to obtain a value from a window, we need to decide when to run the computation, thus trigger comes. Some of the possibilties (can be combined):
- watermark progress - compute the final window result once the watermark passes the window boundary
- event time progress - compute window results multiple times, with a specified interval, as the watermark progresses
- processing time progress - compute window results (multiple times) basing on a given interval measured against wall-clock time
- punctuations - data-dependent
Why Flink - The evlolution of Streaming Processing
- Apache Storm - Record acknowledgements: each record that is processed from an operator sends back to the previous operator an acknowledgement that it has been processed. => problems with application dedupe; low throughput and problems with flow control
- Apache Spark Streaming - Micro batches: in order to overcome the complexity and overhead of record-level synchronization that comes with the model of continuous operators that process and buffer records, a continuous computation is broken down in a series of small, atomic batch jobs (called micro-batches). Still left much to be desired: Programming model, flow control, latency.
- Google Cloud Dataflow - Transactional updates: implements the concept that atomically log record deliveries together with updates to the state.
- Apache Flink - Distributed Snapshots: combines the benefits of following a true continuous operator model (low latency, flow control, and true streaming programming model) with high throughput, and exactly-once guarantees provable by the Chandy-Lamport algorithm.

Great article referenced here
Typical Usecases
Event-driven applications
A stateful application that ingest events from one or more event streams and reacts to incoming events by triggering computations, state updates, or external actions Use Cases:
- Tora/ECDL: managed platform to derive real-time and life-cycle variable metrics.
- UMP: collects metrics, events and logs from multiple sources, feeding into preprocessing and alerting engine to enrich, normalize, dedupe, alerting, etc.
- Risk: fraud detection
Data analysis applications
With a sophisticated stream processing engine, analytics can also be performed in a real-time fashion. Instead of reading finite data sets, streaming queries or applications ingest real-time event streams and continuously produce and update results as events are consumed.
- Live report: ad-hoc analysis of live data from buyer or sellers.
- DSS: empower analysts to run comprehensive, production-quality streaming analytics.
Data pipeline applications
Extract-transform-load (ETL) is a common approach to convert and move data between storage systems. Often ETL jobs are periodically triggered to copy data from from transactional database systems to an analytical database or a data warehouse. Flink jobs operate in a continuous streaming mode instead of being periodically triggered. Hence, they are able to read records from sources that continuously produce data and move it with low latency to their destination.
- Data platform: process transactional streaming merge logic for LCR (Latest Change Record) to FCR (Full Change Record).
- Search: build real-time search indexing.
Programming Model
Abstraction Level
 The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStream API via the Process Function.
In practice, most applications would not need the above described low level abstraction, but would instead program against the Core APIs like the DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets).
The Table API is a declarative DSL centered around tables, follows the (extended) relational model: Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc.
The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStream API via the Process Function.
In practice, most applications would not need the above described low level abstraction, but would instead program against the Core APIs like the DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets).
The Table API is a declarative DSL centered around tables, follows the (extended) relational model: Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc.
Programs and Dataflows

Parallel Dataflows
 A stream has one or more stream partitions, and each operator has one or more operator subtasks. The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
The number of operator subtasks is the parallelism of that particular operator. The parallelism of a stream is always that of its producing operator. Different operators of the same program may have different levels of parallelism.
A stream has one or more stream partitions, and each operator has one or more operator subtasks. The operator subtasks are independent of one another, and execute in different threads and possibly on different machines or containers.
The number of operator subtasks is the parallelism of that particular operator. The parallelism of a stream is always that of its producing operator. Different operators of the same program may have different levels of parallelism.
Get Started with Flink
Setup your local environment
- Dependency
JDK: Java 8
Flink: 1.7.0
brew install apache-flink
Download and unpack from download page, pick up a binary package.
./bin/start-cluster.sh
Log files are put in logs folder.
A simple user story
Create a simple fraud detection job for stolen credit card. Usually stolen credit card appears with a small amount purchase, immediately followed by a large amount one. Definition:
- small: less than 1.0
- large: more than 500.0
- immediate time interval: within one minute
Homework
Q: What’t time is used in the sample project? Q: If we need to trigger alert when an account creates more than 10 transactions within 5 minutes..